Pipelining
Intro
In a recent blog, in part we spoke about how a given tile scheduler might affect the speed of your kernel. But throughout that blog, we never spoke to the constraints that exist upon the A or B tiles themselves or their roles in the actual matrix-multiply portion of a gemm kernel. The aim of this blog is to speak more to various ways we add "depth" to a gemm (CuTeDSL) kernel.
Hardware realities
Asking ourselves "what tile shape should our gemm kernel use" is asking several questions over the underlying hardware itself. An H100 has 227KB of shared memory, so given we load our tiles into shared from global memory, this sets a hard cap on the number of bytes we can store at any given time. Assume our kernel is in bfloat16, then this implies that we can support (M_tile * K_tile + N_tile * K_tile) * sizeof(bf16) <= 227 * 1024 as A => [M, K], B => [N, K] without taking into consideration other smem needs. So already we can turn three separate knobs.
Does the hardware itself impose any constraints on these knobs, or give us others?
In Hopper, new wgmma (warpgroup matrix multiply-accumulate) instructions were added that allow for a warpgroup (4 warps) to collectively execute instructions. Previously, through regular mma instructions, in order to use the hardware's tensor cores, you needed to load your data to local registers. Per SM, there are a finite number of registers, and filling them up with matrix tiles would create register pressure and limit the CTA occupancy, where fewer CTAs could run simultaneously. With wgmma, the tensor cores can both stream data from shared memory, which bypasses register files, and also execute asynchronously. This asynchronous execution is interesting because the instructions give us a way to hide the latency of the tensor cores (there are four per SM on an H100) executing the matrix multiplies, by allowing the warpgroup to queue and wait for different matrix multiplies to complete.
Software abstractions
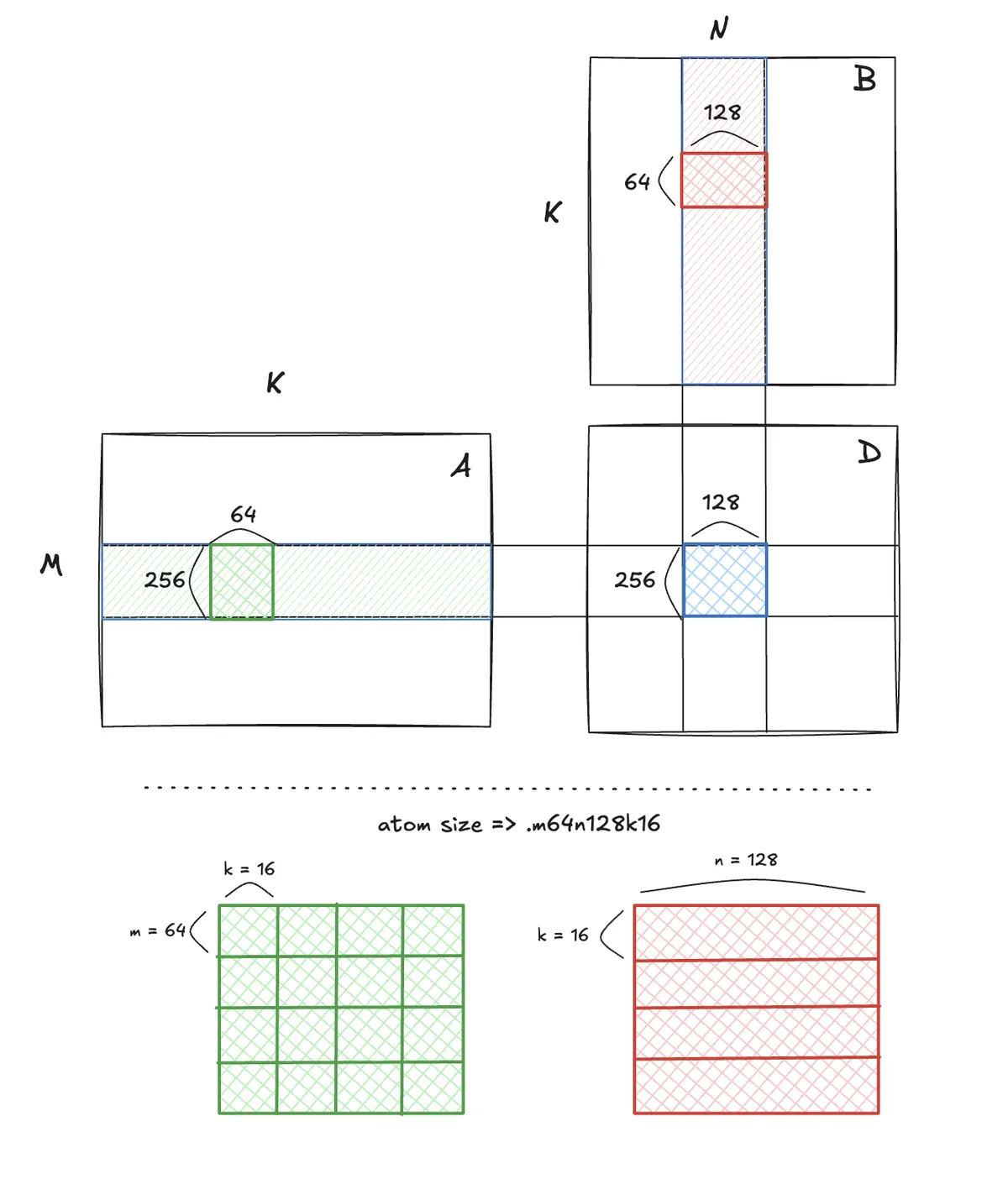
For bf16, we have several options that the shape of these matrix multiplies can be. We notice that for a single matrix multiply, M must be 64, N must be a multiple of 8 between 8 and 256, and K must be 16 (i.e. M, N, and K here form a single atomic unit). With wgmma allowing for asynchronous execution of gemms, the "depth" of our per-tile mma pipeline along the M_tile, N_tile, or K_tile dimensions must now be both considered and informed by these constraints.
A TiledMma is CuTe's generalized way of codifying this relationship. At bottom, aptly named, is an Atom. An atom itself is composed of a Trait and an Op, for us we will create a MmaAtom, which will be composed of a MmaTraits and a MmaOp. A Trait contains the compile-time metadata for a single one of our MMAs while an Op tells you which instruction you are running.
In code, creating an MmaAtom looks like the following. Note that the trait is a private method on the op itself.
def make_mma_atom(op: MmaOp, ..., **kwargs) -> MmaAtom:
trait = op._make_trait(..., **kwargs)
return MmaAtom(op, trait)
While an Op is similar to a schema in that it is defined by compile-time shapes, dtypes, major-modes, etc, a Trait is similar to wiring, describing how threads, registers, and memory connect to that instruction. Under the hood, when creating our TiledMma, a MmaF16BF16Trait object will be created that provides answers to questions like "for a given thread, which register fragments of A and B does it own" or "what is the instruction tile shape (i.e. M, N, and K sizes)". The trait itself is derived from the op (in our case for our bfloat16 setup, a MmaF16BF16Op).
For instance, eventually, when we call cute.gemm, the trait is used to know how much work one cute.gemm call covers (i.e. (64, 128, 16) for .m64n128k16). Traits also allow us to set whether or not some k-tile will accumulate their value (C += A @ B) or not (C = A @ B). A trait is basically the answer sheet for "given this one WGMMA instruction, how do threads, registers, and memory connect to a matrix tile?" The trait says how the mma is wired, and it is the role of the MmaOp to say which instruction will be used.
A TiledMma takes this singular, atomic "bundle", and in keeping with CuTe layouts, tiles the MmaAtom according to a provided layout.
Here's a way to visualize the relatinship between tiles and mma atoms.
In CuTeDSL, creating a TiledMma is as trivial as (that's the actual function name):
def make_trivial_tiled_mma(
a_dtype: Type[Numeric],
b_dtype: Type[Numeric],
a_leading_mode: OperandMajorMode,
b_leading_mode: OperandMajorMode,
acc_dtype: Type[Numeric],
atom_layout_mnk: Tuple[int, int, int],
tiler_mn: Tuple[int, int],
a_source: OperandSource = OperandSource.SMEM,
) -> cute.TiledMma:
...
mma_op = MmaF16BF16Op(
a_dtype,
acc_dtype,
(*tiler_mn, 16),
a_source,
a_leading_mode,
b_leading_mode,
)
...
return cute.make_tiled_mma(cute.make_mma_atom(mma_op), atom_layout_mnk)
The mma trait is what tells each thread how it connects to the atom. In a TiledMma you apply that at runtime with a per-thread slice and fragments:
thr_mma = tiled_mma.get_slice(thr_idx)
acc = cute.make_rmem_tensor(thr_mma.partition_shape_C(tile_mn_shape), cutlass.Float32)
tCrA = tiled_mma.make_fragment_A(thr_mma.partition_A(sA))
tCrB = tiled_mma.make_fragment_B(thr_mma.partition_B(sB))
partition_A(sA) and partition_B(sB) take the staged smem tiles and return a view of the buffer that thr_idx owns inside the CTA tile (i.e. it answers who is allowed to address which region for the multiply). make_fragment_A / make_fragment_B then re-express that view in the mma operand layout that wgmma expects (still sourced from smem here). acc is separate, however. partition_shape_C only supplies the shape and make_rmem_tensor backs it with per-thread accumulator registers where the warpgroup accumulates the result.
Multistage
Depthwise, within a single tile, is not the only knob we can turn in terms of depth. Just as wgmma allows for asynchronous matrix multiply and tile-wise depth, the asynchronous nature of TMA (Tensor Memory Accelerator) and transaction barriers allow for inter-tile depth. This buffering of multiple tiles allows us to potentially fully hide the latency of loading data from gmem and avoid costly stalls where warps are waiting for memory operations to complete as discussed previously. Speaking to our tile-shape question above, this "deeper" pipeline (one with more stages) would allow for less stalls between execution on a given tile at the expense of a smaller tile. In order to take advantage of this, aptly named once again, is the Pipeline class of functions, and for us because we are using TMA, PipelineTmaAsync.
At base, a pipeline is a synchronization mechanism whereby two separate groups of agents can provably ensure that one group of agents cannot access some shared resource while the other is using it. Thinking through what a pipeline ought to do in our case may help our intuition when we read code further below.
Our Agents will be some number of cooperating threads in some number of warps, either producing or consuming tiles. We know that there can potentially be many more tiles that we need to load and consume than there is space for those tiles. For instance, say with the tile shapes we chose for our A and B tensors that we have space in smem for 5 stages, where one stage has capacity for the sum of bytes for A and B. At the same time, our K dimension is large enough that it will take, say, 100 iterations to cover a full stripe of A and B. A natural solution to this is a circular buffer. We can have two circular buffers where one holds the actual A and B data and the other holds references to the synchronization mechanisms that control access to those data buffers.
Our producer therefore needs to know, at the very least, whether it can overwrite some chunk of memory. Initially, it will happily load all 5 stages worth of data because the consumer clearly needs actual data, but then how will the producer know it can overwrite that data with new data because the consumer has finished using the old data? On the other hand, the consumer needs to know whether some data that it's looking at is new and thus ready to be computed over. How will the consumer know not to consume old data but to wait until the data is fresh?
From the point of view of the producer, it needs to know that all consumer threads are finished using some stage of data and it needs to be able to tell those same threads that it has fully produced some stage of data. Knowing when the consumer threads are finished implies waiting on some signal. Telling the consumer threads that data is ready implies signaling. From the point of view of the consumer, all threads being finished implies each thread having crossed some finish line and signaling that the threads are finished using some specific data. Knowing that the producer data is ready implies waiting for the producer to signal to the consumer that all the bytes of data we need have arrived.
What makes this all work of course is the signal that is being sent. The producer saying that it is done producing data is a single bit of information. So too is knowing the consumers are done using that data. Crucially, as our stages live in circular buffer of tiles, next-tile-readiness from both sides is not implied by only a simple binary 0 to 1 "phase" change, but a constant 0 to 1 then 1 to 0, etc. So as long as we know the current phase of the underlying synchronization objects that our pipeline is using and we also know the phase that we want these objects to be in, we have a strong guarantee that no contention will occur over our shared resource (i.e. our tile data).
Now let's turn our attention to actual code.
Creating a pipeline makes sense given what we've talked about:
pipeline_obj = pipeline.PipelineTmaAsync.create(
num_stages=num_stages,
barrier_storage=synchronization_object_smem_storage,
producer_group=pipeline.CooperativeGroup(pipeline.Agent.Thread, producer_arrive_cnt),
consumer_group=pipeline.CooperativeGroup(pipeline.Agent.Thread, consumer_arrive_cnt),
tx_count=number_bytes_to_load_in_tma,
...,
)
We need to know the number of stages in order to know the number of synchronization objects we'll need to track, the number of threads per producer and consumer group to ensure each group has "made it past its finish line", and the number of bytes that the producer will be producing. That the producer_arrive_cnt and consumer_arrive_cnt may be different speaks the fact that our kernel can work with a single warpgroup, an equal amount of producer and consumer warpgroups, or even a single producer and multiple consumer warpgroups. The byte transaction count is very important because, as we've discussed, TMA is asynchronous, so producer threads may have crossed their finish lines before all the data has been fully loaded.
(Note that in the following code, we use warp-specialized producer and consumer groups, though pipelining within a single warpgroup is very much feasible).
Here is our code for the producer and consumer (they are part of separate warpgroups):
class PipelineState:
"""
Pipeline state contains an index and phase bit corresponding to the current position in the circular buffer.
"""
def __init__(self, stages: int, count, index, phase):
self._stages = stages
self._count = count
self._index = index
self._phase = phase
# producer
for k in cutlass.range(kiters):
pipeline_obj.producer_acquire(producer_state)
tma_bar_ptr = pipeline_obj.producer_get_barrier(producer_state)
tma_load(..., smem_idx=producer_state.index, tma_bar_ptr=tma_bar_ptr)
pipeline_obj.producer_commit(producer_state)
producer_state.advance()
...
# consumer
for k in cutlass.range(kiters):
pipeline_obj.consumer_wait(consumer_state)
gemm(...)
pipeline_obj.consumer_release(consumer_state)
consumer_state.advance()
Here, the producer and consumer share the same pipeline objects but different states. A PipelineState is the object within our kernel that allows us to track the current phase (i.e. are we ready to move onto the next tile) and index (i.e. what is our most currently being-worked-on tile). If we imagine a thread in each of the producer and consumer groups, and the (simplified) journey each will initially take:
# producer thread journey
def producer_acquire():
sync_object_empty.wait(producer_state.index, producer_state.phase)
sync_object_full.arrive(producer_state.index)
# consumer thread journey
def consumer_wait():
sync_object_full.wait(consumer_state.index, consumer_state.phase)
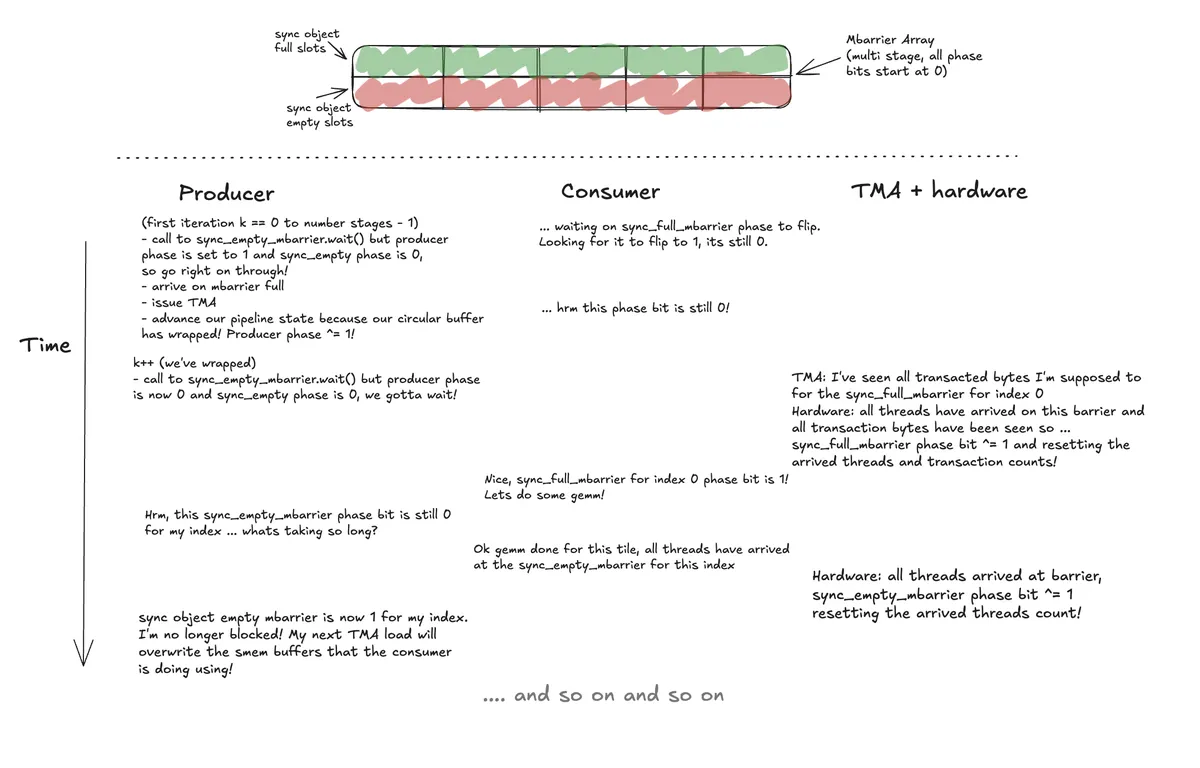
The synchronization object that we will use to solve this problem is an mbarrier. Needing two synchronization primitives per stage speaks to exactly the two questions we are asking. Namely, from the producer, "can this smem slot be overwritten" (i.e. sync_object_empty), and from the consumer, "can this data be used in this smem slot" (i.e. sync_object_full), with the phase bit playing a crucial role in each question. The producer threads, as spoken to above, will wait for the consumer threads to finish work over some stage, then begin their "new race" of loading data via TMA.
Looking at the semantics of what these wait and arrive calls will eventually turn into:
def mbarrier_wait(mbar_ptr: Pointer, phase: Int) -> None:
"""
Waits on a mbarrier with a specified phase.
"""
nvvm.mbarrier_try_wait_parity_shared(
mbar_ptr.to_llvm_ptr(),
Int32(phase).ir_value(),
Int32(timeout_ns).ir_value(),
)
def mbarrier_arrive_and_expect_tx(mbar_ptr: Pointer, num_bytes: Int):
"""
Arrives on a mbarrier and expects a specified number of transaction bytes.
"""
nvvm.mbarrier_txn(
mbar_llvm_ptr,
Int32(num_bytes).ir_value(),
kind=nvvm.MBarrierTxnKind.ARRIVE_EXPECT_TX,
space=nvvm.MBarrierSpaceKind.CTA,
)
Looking at the arrive call, we are specifying to the underlying mbarrier to flip its phase bit (signaling completion) only when num_bytes bytes have been transacted and our specified number of threads have arrived. This makes intuitive sense as the consumers can only begin their work when all the data has been loaded by the asynchronous TMA from the producer warps. The hardware automatically and atomically issues an mbarrier reset whereby, in our case, the number of bytes expected is reset and the phase bit flipped.
Now looking at the wait call, waiting on an mbarrier with a specified phase is to wait for the phase in the underlying barrier itself to not be the phase you specify (i.e. you wait if the mbarrier phase is 0 and you specify 0 and do not wait if the mbarrier phase is 1 and you specify 0). Said another way, you wait at a barrier until the phase with a given parity has completed (note that mbarrier_wait calls nvvm.mbarrier_try_wait_parity_shared).
This has clear implications for how we initialize our producer and consumer PipelineState object's phases in software. On initialization, a barrier has a phase bit set to 0. So, if we initialize both of our producer and consumer PipelineState phases also to 0, both groups will wait in perpetuity.
The solution is to initialize our producer state's phase to be out of phase with the underlying sync_object_empty mbarrier's phase. On the first stage amount of iterations, our producer group will immediately go through both the sync_object_empty.wait and sync_object_full.arrive and issue its TMA instructions. After all producer threads have arrived across the sync_object_full barrier and TMA has decremented its expected transaction bytes to zero, the sync_object_full phase bit will be flipped and the consumer threads will be unblocked.
Importantly, let's think through the state our system will be in when we "loop back" on the circular buffer (i.e. our pipeline state has advanced such that some slot in the circular buffer is being reused). The call to advance has set the producer state's phase to 0, and until the consumer finishes its gemm computation as talked about above, the sync_object_empty phase is also 0. Unlike the producer op type which is a PipelineOp.TmaLoad, the consumer op type is an PipelineOp.AsyncThread. This is to say that the arrive semantics for TMA are based on transaction bytes seen but for the consumer based on threads arrived. So, when all the threads in the consumer group have crossed their finishes lines, the sync_object_empty flips its phase, the next iteration of TMA loads can occur, and the entire process repeats.
A visual of this flow might look something like:
A quick optimization note. If you look at the code for producer_acquire and consumer_wait, each take an optional token (try_acquire_token / try_wait_token). The token comes from an earlier producer_try_acquire or consumer_try_wait, which both lower to a single mbarrier_try_wait, which does one non-blocking probe of the mbarrier phase. If the token is True, the subsequent acquire/wait does not call mbarrier_wait at all (the spin loop path won't be taken). If the token is False, you pay that extra probe and still enter the blocking spin. So, we do the same phase-bit check, but split it into poll once and block only if needed. This would only pay off when P(success) × (avoided spin) > P(failure) × (extra probe) on each side. For the consumer, success means the next smem stage was already full after your MMA. For the producer, success means the next stage was already empty after your load. In a well-tuned K-pipeline these peeks would succeed often, but if one side almost always fails, the pipeline is probably mismatched and try-wait may be slightly worse than always waiting.
Putting this together, below are some kernel runtimes. We fix N at 128, show speedups relative to cuBLAS, and note the number of stages in parentheses. As briefly mentioned above, kernels can deploy multiple consumer warpgroups. We know that a single MmaAtom has a shape of .m64nXYZk16. So, if our tile shape is (256, 128, 64), we are looking at 16 matrix-multiplies per tile.
But as we push our [M, N] tile dimensions higher, we hit a structural limit with registers. Hopper’s wgmma requires the warpgroup to hold the accumulation state in a highly specific, fragment layout, and as the tile area grows, the register allocation per thread will scale layout proportionally. If a single warpgroup tries to ingest a massive M dimension, it quickly hits the 256-register-per-thread hardware limit. Implementing a multi-consumer warpgroup architecture allows us to spatially split the M dimension. By halving, quartering, etc the row allocation per warpgroup (i.e. warpgroup 0 taking the top half of the 256 M rows and warpgroup 1 taking the bottom half), we reduce the per-thread accumulator register requirement. This division of labor is exactly what allows the larger tile shapes seen in the different configurations below.
Notably, we hit a sweet spot when stage depth and k-depth is around 4. Too few stages and we don't hide latency well between tiles, but too many stages we pay a high barrier cost. (Deeply profiling the kernel is beyond the scope of this post).
| M tile \ K depth | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 |
|---|---|---|---|---|---|---|---|---|
| 64 | 0.48× (18) | 0.52× (9) | 0.44× (6) | 0.54× (4) | 0.43× (3) | 0.54× (3) | 0.34× (2) | 0.42× (2) |
| 128 | 0.68× (13) | 0.73× (6) | 0.64× (4) | 0.68× (3) | 0.42× (2) | 0.44× (2) | 0.39× (1) | 0.46× (1) |
| 192 | 0.75× (10) | 0.88× (5) | 0.70× (3) | 0.55× (2) | 0.47× (2) | 0.51× (1) | 0.46× (1) | 0.55× (1) |
| 256 | 0.86× (8) | 0.98× (4) | 0.48× (2) | 0.60× (2) | 0.49× (1) | 0.56× (1) | 0.51× (1) | 0.58× (1) |
| 320 | 0.12× (7) | 0.13× (3) | 0.12× (2) | 0.12× (1) | 0.11× (1) | 0.12× (1) | 0.12× (1) | exceeds smem |
GEMM pipeline
In our pseudo-code above, the gemm call was very much opaque. In the first part we spoke about how wgmma instructions can be executed asynchronously (similarly to TMA instructions) and in the second part we talked about tile pipelining. Ideally, we want no "bubbles" between consecutive k-tile computation.
But looking at our pseudo-code for the gemm again:
for k in cutlass.range(kiters):
pipeline_obj.consumer_wait(consumer_state)
gemm(...)
pipeline_obj.consumer_release(consumer_state)
consumer_state.advance()
But, if the gemm call uses asynchronous wgmma and the barrier is released on a number of threads arriving, then without some mechanism to know that some wgmma gemms have finished their computations, you have no guarantees that the data for your current (potentially ongoing) gemm isn't being written over. There's a clear race condition. Similarly to how the producer phase bit could only be flipped when both enough threads had arrived and TMA saw enough transaction bytes, so too does the consumer gemm need a guarantee that some slot (i.e. tiles in shared memory) will only be reused when the gemm itself has finished. The solution is to use warpgroup.wait_group (here). Looking at some code makes it more clear:
def gemm(
tiled_mma: cute.TiledMma,
acc: cute.Tensor, tCrA: cute.Tensor, tCrB: cute.Tensor,
state_idx: int,
wg_wait: cutlass.Constexpr[int] = 0,
zero_init: cutlass.Constexpr[bool] = False,
):
warpgroup.fence()
mma_atom = cute.make_mma_atom(tiled_mma.op)
mma_atom.set(warpgroup.Field.ACCUMULATE, not zero_init)
for mma_k in cutlass.range_constexpr(k_subtiles):
cute.gemm(mma_atom, acc, tCrA, tCrB, acc)
mma_atom.set(warpgroup.Field.ACCUMULATE, True)
warpgroup.commit_group()
warpgroup.wait_group(wg_wait)
The dance played within this function is in four parts. The call to fence synchronizes the warpgroup and opens the "window" for some amount of asynchronous wgmma (cute.gemm) calls, and finally, commit_group closes the "window". Crucially, wait_group is to be called before the consumer_release of the slot that was being used.
However, The clear issue is that if we always wait for our asynchronous gemm to finish before moving on, then this is effectively just a synchronous function. The key to maintaining a bubbleless tensor core pipeline (i.e. the tensor cores are always ready to consume another smem stage of data) is warpgroup.wait_group(wg_wait), where the call to wait_group will only block if there are more than wg_wait wgmma groups that are in-flight. For instance, setting wg_wait = 1 guarantees that the previous group has completed and the current one is still running. And so, if k-tile iterations 0 then 1 (slots 0 and 1) both issued gemms, then on iteration 1 the consumer_release would release the lock for slot 0. This can be wired up like:
k_stagger_mmas = 1
stagger_consumer_state = consumer_state.clone()
for k in cutlass.range(k_stagger_mmas):
tma_load_pipeline.consumer_wait(consumer_state)
gemm(tiled_mma, acc, tCrA, tCrB, consumer_state.index, wg_wait=1, zero_init=k==0)
consumer_state.advance()
for k in cutlass.range(k_stagger_mmas, kiters, unroll=1):
tma_load_pipeline.consumer_wait(consumer_state)
gemm(tiled_mma, acc, tCrA, tCrB, consumer_state.index, wg_wait=1, zero_init=False)
tma_load_pipeline.consumer_release(stagger_consumer_state)
stagger_consumer_state.advance()
consumer_state.advance()
warpgroup.wait_group(0)
for k in cutlass.range(k_stagger_mmas):
tma_load_pipeline.consumer_release(stagger_consumer_state)
stagger_consumer_state.advance()
Crucially, notice in the main loop we called consumer_release on the stagger_consumer_state whose index is trailing the consumer_state index by 1 (i.e k_stagger_mmas).
Conclusion
Hopper gemm depth shows up in several places within your kernel, and here we've spoken to a few. An atom partitions your tile into subtiles, multiple stages allow you to hide the latency of loading data behind perform matrix multiplies, and in-flight wgmma allows you to queue tiles to your tensor cores. Pipelining, while helpful, is not strictly better. Altering the tile shape, the number of stages, or the k-depth are all knobs you can turn when tuning your kernel.