Gemm Epilogue
Introduction
The core function of an epilogue is to write data to gmem. The accumulator values sit in registers in the layout chosen by wgmma, but the final output needs to land in global memory as a normal (M, N) tensor, usually in a different dtype. In this post, we’ll look at the machinery that bridges these worlds, including retiled accumulator fragments, stmatrix stores into shared memory, and TMA stores from shared memory back to global memory.
Storing data
The main function of a gemm epilogue is to correctly store our output tile data. But as we spoke about in a previous blog, mma output accumulates in a specific subtile layout within a somewhat arbitrarily sized (M,N) output tile shape. So we'll need to convert our data to the correct layout so we can store our output correctly and potentially change the output data's datatype. Furthermore, because we'll be using TMA to store our data from smem to gmem (as opposed to storing our accumulated output directly from registers to gmem), we'll need to create the building blocks with which to do that.
To start, lets take for granted that we have built the functionality to map our wgmma accumulator layout to the final output layout that we will write to gmem with. We'll speak more to below. Let's assume we've accumulated into registers, of datatype cutlass.Float32, across our mma warps an output tile of shape (M, N) == (128, 256) and want to write back to gmem with datatype cutlass.BFloat16.
From the previous blogpost we found that developing a pipelined kernel with a certain number of k-stages allowed us to hide the latency of some TMA load behind the matrix multiplies. This staging took up around 85% of our smem capacity. As we spoke about, there's a tradeoff between k-stages and tile-shape. Not spoken about in that blogpost though, pushing your k-stage smem capacity too far may leave little room for the epilogue, especially if you writing a persistent kernel where you can't just repurpose your A or B smem storage for the epilogue.
Given that we found that supporting larger tiles supported by multiple consumer (mma) warpgroups performed the best, we're forced to tile our output and issue multiple TMA instructions per output tile. Fortunately, the same learnings from that previous blogpost can be applied here with regards to creating "depth" in our epilogue. So, lets start with how we might setup our pipeline to facilitate this.
Epilogue pipeline
Here's some code to initially ground us:
for epi_idx in cutlass.range_constexpr(episize):
epi_buffer = epi_idx % num_epi_stages
regs_data = tRS_rAcc[..., epi_idx].load()
if is_tma_warp:
with cute.arch.elect_one():
epi_store_pipeline.producer_acquire()
epi_nbarrier.arrive_and_wait()
cute.copy(epi_tiled_copy, regs_data, smem_data[..., epi_buffer])
cute.arch.fence_view_async_shared()
epi_nbarrier.arrive_and_wait()
if is_tma_warp:
with cute.arch.elect_one():
tmaCopyBuffer(..., epi_buffer)
epi_store_pipeline.producer_commit()
The pipeline (epi_store_pipeline) we'll be using for our TMA will be PipelineTmaStore. The underlying synchronization object that is used in the PipelineTmaStore is a TmaStoreFence, where epi_store_pipeline.producer_acquire() -> TmaStoreFence.wait() and epi_store_pipeline.producer_commit() -> TmaStoreFence.arrive(). The wait call will call cute.arch.cp_async_bulk_wait_group(self.num_stages - 1) and block until the number of still-pending committed groups is <= num_stages - 1, similar to how during our asynchronous wgmma instructions the call to warpgroup.wait_group(wg_wait_cnt) would wait until at most wg_wait_cnt groups were in-flight to unblock.
The epi_store_pipeline.producer_commit() is conceptually like an ordered per-issuing-thread queue of committed async bulk-copy groups. The async-group mechanism means that the issuing thread specifies a group of asynchronous operations (TMA copies in our case), called an async-group, using a commit operation and tracks the completion of the group with a wait operation. We are safe to use a circular buffer to hold our subtiles because all async-groups committed by an executing thread always complete in the order in which they were committed. And when the async-group completes, the asynchronous operations that belong to that group are also complete.
Note that only one thread across all of your mma warpgroups needs to directly interact with the pipeline object, but because this thread might block waiting for an epilogue stage to open up, we need another barrier object for all threads across our mma warpgroups to wait on. This is our epi_nbarrier, which is a NamedBarrier. A NamedBarrier performs synchronization and communication within a CTA.
epi_nbarrier = pipeline.NamedBarrier(
barrier_id=epilogue_barrier_id,
num_threads=num_epi_warps * cute.arch.WARP_SIZE
)
As discussed here, each CTA has 16 barriers, numbered 0 to 15. Note that barrier id 0 is used for sync_threads. When num_threads amount of threads reaches the barrier, the barrier completes, the waiting threads are restarted, and the barrier is reinitialized so it can be reused. Once we pass that first barrier point, each epilogue thread knows the next stage is available to cute.copy their next portion of accumulator registers to smem.
The call to cute.arch.fence_view_async_shared plays a crucial role in ensuring a clear ordering between threads writing to smem (via cute.copy) and TMA writing from smem to gmem. The purpose of the fence call is to make the smem writes just written by the calling thread visible to later async proxy operations, such as TMA. The second epi_nbarrier.arrive_and_wait() ensures all the epilogue threads have done this before the TMA copy is initiated, which is to say that all of our data has landed in smem. An async proxy is a type of memory proxy, which is a label applied to a method of memory access. Because rmem to smem cute.copy uses the general proxy and TMA copies use the async proxy, a proxy fence is required to synchronize memory access ordering between them.
Now that we know about the synchronization primitives that will allow us to store our data, lets look into how we'll set this data to be written.
Epilogue tiling
The code above hides a lot of complexity when it comes to moving data from the accumulator registers to smem. Looking again at the register fragment layout (reproduced below for ease) for our accumulator matrix we see that each warp in our warpgroup is responsible for 16 consecutive rows and all columns of our tile (M, N). We notice that each "atomic" unit in that image, per warp, is an 8x8 chunk of data, which is exactly the op shape that is described by the StMatrix8x8x16bOp. Furthermore, from that image, we notice a clear thread-data access pattern. In a (64, 16) chunk of data, thread 0 is responsible for offsets 0, 1, 8, 9, 128, 129, 136, and 137.
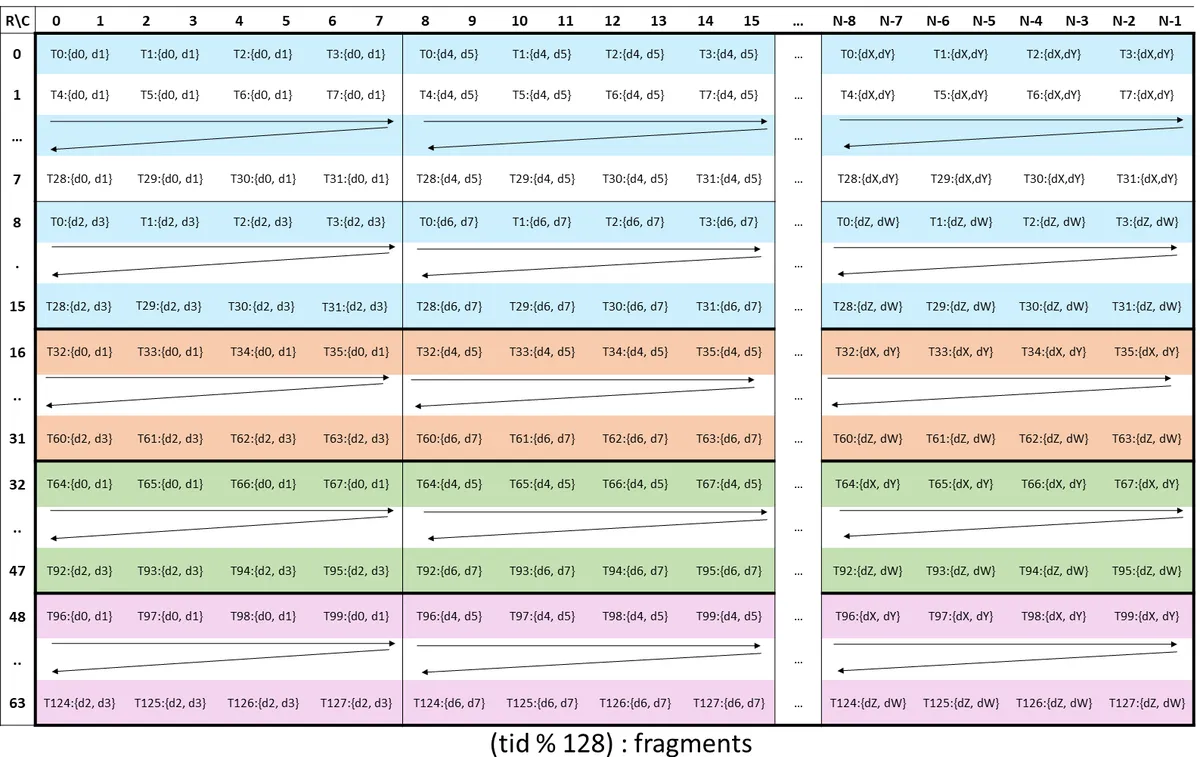
This is important for a couple of reasons. When you create a StMatrix8x8x16bOp op, you can set num_matrices=4 so that instead of writing back to smem 2 16-bit (32 bits) values, you can write back 8 16-bit (128 bits) values across 4 matrices in one copy operation, covering all of those aforementioned indices. So, assuming we ran our consumer pipeline with 2 mma warpgroups, this means we can write 32 (threads per warp) * 8 (total consumer warps) * 8 = 2048 values from our accumulator registers to smem in one copy operation. This directly informs the shape of our epi-tile, i.e. the shape of each buffer in smem that TMA will use. Because, as mentioned above, our output tile shape we chose is (128, 256), this implies that each warpgroup will be responsible for 64 rows. Therefore, the smallest epilogue smem buffer that aligns with the StMatrix8x8x16bOp(..., num_matrices=4) we are using is (128, 16). CuTe then uses the same logical smem layout for both sides of the epilogue. The register-to-smem stmatrix copy writes into this staged tile, and the TMA store reads that staged tile back out to global memory. There are tradeoffs to choosing our epi-tile shape, though.
Let's compare what an epi-tile shape of (128, 32) and (128, 16) might cost us. The (128, 32) shape would need two stmatrix.x4 applications per warp versus one for (128, 16). Using (128, 16), we would get more pipeline depth and smaller staging chunks at the cost of double the number of barrier/fence instructions, double the number of TMA store issues, and double the number of epilogue loop iterations. We could even make the epilogue stage much smaller if we wanted. Given the hardware store atom is an 8x8 matrix, the absolute minimum is one atom-sized tile.
Comparing a few different epilogue tile shapes, keeping num_matrices=4 and the epilogue smem footprint constant.
| Tile shape | Persistence | Stages | Loop iters | Runtime | L2 GB | TMA stores | Long SB |
|---|---|---|---|---|---|---|---|
(128,64) |
none | 2 | 4 | 1.410 ms | 11.03 | 8,192 | 15.75% |
(128,32) |
none | 4 | 8 | 1.424 ms | 11.09 | 16,384 | 15.16% |
(128,16) |
none | 8 | 16 | 1.429 ms | 10.86 | 32,768 | 15.24% |
(128,64) |
dynamic | 2 | 4 | 1.404 ms | 11.81 | 8,192 | 14.31% |
(128,32) |
dynamic | 4 | 8 | 1.401 ms | 10.93 | 16,384 | 13.93% |
(128,16) |
dynamic | 8 | 16 | 1.418 ms | 11.56 | 32,768 | 15.68% |
These numbers show that epilogue tile shape is not just a smem staging choice. It also interacts with the scheduling strategy. In the non-persistent kernel, the largest epilogue tile wins because fewer chunks means fewer barriers, fences, and TMA store issues. NCU confirms part of this tradeoff. Shrinking the tile from (128, 64) to (128, 16) increases TMA store instructions from 8,192 to 32,768.
In the dynamic-persistent kernel, the middle configuration wins. The persistent CTA's producer can move on to loading the next tile while the current tile’s epilogue drains through TMA stores, so some extra staging depth helps. Smaller is not always better though. The (128, 16) tile issues the most TMA stores and L2 write requests, and it has the worst long-scoreboard (a warp cannot issue its next instruction because it's waiting on a long-latency dependency to complete, usually a memory operation) stalls among the persistent runs. The (128, 32) tile lands in the middle, with enough chunks to overlap stores with later work, but not so many that TMA and L2 issue overhead dominate.
A quick note on our accumulator layout. The wgmma accumulator fragment already has the same shape as the values that each thread owns. For our (64, 256) wgmma C atom, the value side of the C thread-value layout has shape (2, 2, 32). For a fixed thread, the first 2 is the pair of adjacent columns, the second 2 is the pair of row groups separated by 8 rows, and the 32 walks across the N dimension in 8-column blocks. For example, thread 0 owns d0,d1, then d2,d3, then repeats that pattern at columns 8,9, 16,17, and so on across N=256. This is exactly what the image we have been looking at describes.
So when we do:
thr_mma = tiled_mma.get_slice(tidx)
acc_layout = thr_mma.partition_shape_C(tile_mn)
It makes sense that the per-thread accumulator layout is of shape (2, 2, 32). It is the value side of the wgmma C TV layout after fixing the thread coordinate. To use StMatrix8x8x16bOp(..., num_matrices=4), we reshape that value layout from (2, 2, 32) into (2, 2, 2) repeated 16 times. This reinterprets the same per-thread register values in the source-fragment shape expected by stmatrix.x4. The leading (2, 2, 2) is the 8 values one lane contributes to one stmatrix.x4 source fragment as described above. The remaining 16 is the sequence of such fragments across the N direction. From there, changing the epilogue tile shape is mostly a CuTe layout choice. With shapes (128, 16), (128, 32), and (128, 64), we group progressively more of these N-fragments into a single staged TMA store tile.
Conclusion
The epilogue is easy to describe as “just the store,” but most of the interesting work is in making that store line up with the hardware. The accumulator starts in a wgmma register layout, gets reinterpreted into stmatrix fragments, lands in staged smem tiles, and then drains through TMA. The tile shape we choose for that staging is a real performance knob, because it changes how much synchronization, TMA issue overhead, and overlap the kernel gets.