PDL and TVM-FFI
Intro
This post is about the bubbles in you see in your Nsys traces and a couple interesting methods (tvm-ffi and Nvidia's Programmatic Dependent Launch) that aim to close those gaps.
TVM-FFI
The Nvidia docs strongly suggest compiling your CuTe kernel with tvm-ffi because of its ability to reduce launch overhead. The couple images below show an nsys trace with (top) and without (bottom) tvm-ffi. The chain of kernel calls we'll be speaking to throughout this blog take the following shape where each matrix is a square matrix:
def kernel_chain(...):
zero_memory(loc0)
zero_memory(loc1)
gemm1(A, B, output=C, mem=loc0, ...)
gemm2(C, D, output=E, mem=loc1, ...)


At size 256 for our square matrices, the average time to complete our kernels is 110 microseconds without tvm-ffi and 22 microseconds with it. The gap between the two gemms is 40us without and 1us with. This is reason enough to prefer compiling with tvm-ffi, but to appreciate tvm-ffi we need to first speak to fake tensors.
In CuTeDSL, conceptually a _FakeTensor exists to describe a tensor type/signature without owning actual data. This includes information like dtype, rank, shape/stride/layout constraints, etc. Fake tensors allow you to compile your kernel like:
m = cute.sym_int(divisibility=8)
n = cute.sym_int(divisibility=8)
A_fake = cute.runtime.make_fake_compact_tensor(
cutlass.BFloat16, (m, n), stride_order=(1, 0), assumed_align=128,
)
fn = cute.compile(YourKernel, A_fake, ...)
Meaning, you as the developer promise to pass a bf16 compact row-major tensor whose dimensions are dynamic but divisible by 8 and whose pointer is aligned to 128 bytes. Fake tensors act as a compile-time signature language for CuTe tensors, allowing the compiler to know what runtime tensors are allowed to look like. For instance, dynamic shapes allow you to note some dynamic batch size as opposed to compiling a kernel to a specific batch size.
Sensibly, tvm-ffi is the means through which your compile-time, developer-promise is codified into runtime guarantees. Without tvm-ffi, as the nsys trace makes clear, the overhead of host side tensor adapters, CuTe wrappers, argument list construction, very much dominates wall-clock-time. With tvm-ffi, the CuTe JIT call boundary effectively shifts from "Python objects need to converted into CuTe runtime descriptors per call" to "arguments get passed through a compact, typed, ABI-stable foreign-function-interface (ffi)".
This can be seen by tracing the cute.compile path in cutlass.py. When enable_tvm_ffi is set, Cutlass first derives a tvm-ffi parameter spec from the compile-time fake tensor signature. With this fake parameter spec, Cutlass registers a post-compile hook which adds a tvm-ffi stub to the MLIR module. Once the hook has added that stub and the module is compiled, the function returned to Python is wired to enter through that stub, so calling the kernel goes through tvm_ffi.Function.__call__ instead of the normal CuTe JIT executor path.
The speedups from this path look a lot like the speedups you get from Cuda graphs. The difference being that Cuda graphs reduce host overhead by recording a static launch sequence and replaying it, whereas tvm-ffi reduces host overhead while keeping the launch path dynamic (i.e. Python still calls the kernel directly, but the call crosses into a much thinner native ABI path).
| Launch mode | TVM-FFI | PDL | Average chain time |
|---|---|---|---|
| Eager | No | No | 109.797 us |
| Eager | Yes | No | 22.210 us |
| CUDA Graph | No | No | 19.833 us |
| CUDA Graph | Yes | No | 20.032 us |
| Eager | Yes | Yes | 21.636 us |
| CUDA Graph | No | Yes | 18.876 us |
| CUDA Graph | Yes | Yes | 18.986 us |
PDL (Programmatic Dependent Launch)
Whereas tvm-ffi and Cuda graphs both attempt to reduce CPU launch overhead, PDL aims to reduce the GPU-side waiting that comes from forcing a dependent kernel to start only after its producer has fully finished. As the Nvidia docs state, PDL allows for a dependent, secondary kernel to launch before the primary kernel it depends on, in the same cuda stream, has finished executing. Using it is actually quite simple with CuTe as well. You tell your second, dependent kernel to griddepcontrol_wait before it begins to use data that depends on your first kernel. And you tell your first kernel to griddepcontrol_launch_dependents once it is "safe" for dependent kernels to begin their work. Notably, PDL has no practical impact if your CPU launch overhead is too great such that your second kernel cannot get enqueued quickly enough for the GPU scheduler to begin issuing instructions for it.

The nsys capture tells this story very clearly. Whereas the gap between start of the second and end of the first kernel with only tvm-ffi was around one microsecond, with PDL the second kernel starts about .25 microseconds before the first one ends.
PDL is generally most useful when the dependent kernel has meaningful work it can do before it actually needs the producer’s output, and when the producer still has enough tail work left for that independent work to overlap with. In a gemm chain, that shape is very natural. The second gemm can launch early and begin its prologue (i.e. initializing scheduler state, setting up TMA descriptors, preparing its pipelines, etc) while the first gemm kernel may still be draining its epilogue stores.
Here is a persistent kernel running our kernel-chain code from above over differently sized matrices. Intuitively, the relative speedup that PDL might provide begins to have less of an effect the larger the actual computation within the kernels are.
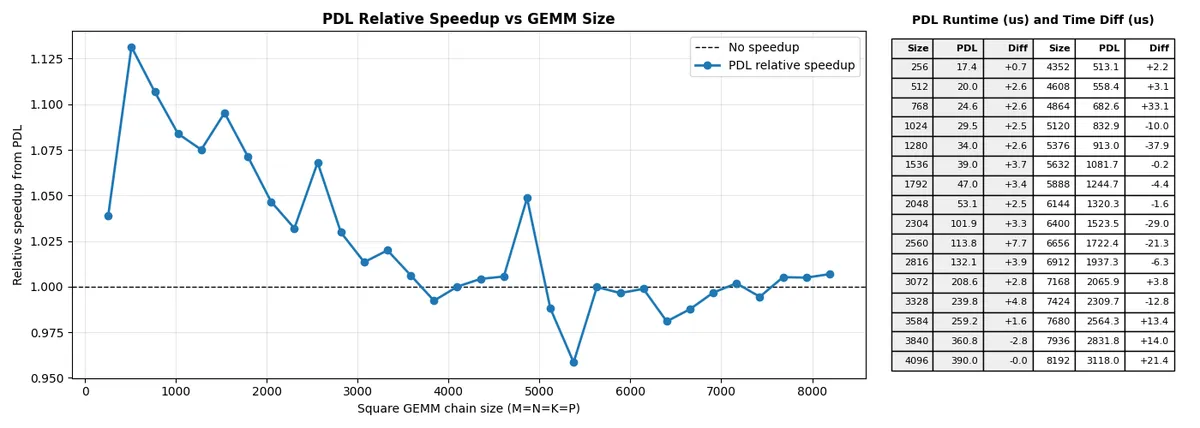
Moreover, if the second kernel immediately needs the first kernel’s result, or if the first kernel has no meaningful tail after signaling dependents, PDL has very little room to help. PDL simply releases the dependent launch before the initial grid has fully terminated. From there, normal Cuda scheduling takes over, so if SM resources are available, CTAs from the dependent kernel can begin running.
Given that, I would've expected a clearer relative improvement from PDL between a persistent and non-persistent kernel due to wave quantization playing a larger role in the latter than the former, which is not what I saw:
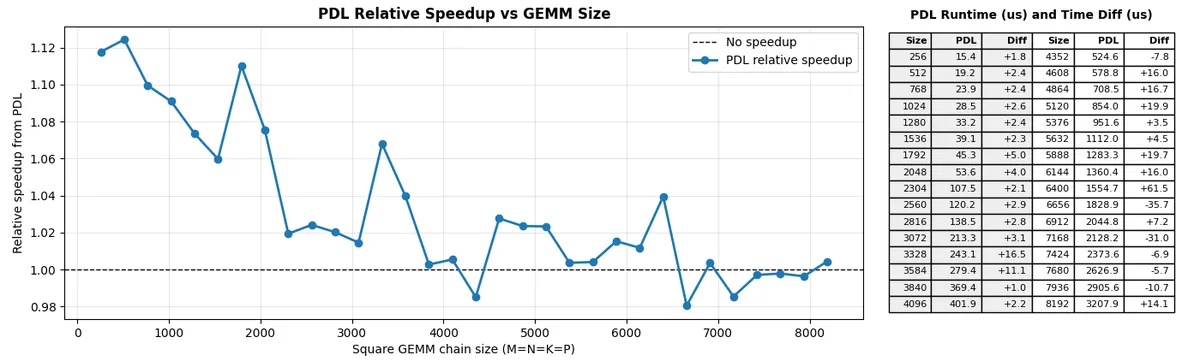
This suggests that, at least for this experiment, the main PDL win has less to do with scheduling and more to do with the secondary kernel's prologue overlapping with the primary kernel's tail.
Conclusion
Tvm-ffi removes most of the host-side launch bubble, making eager CuTe calls look much closer to Cuda graph replay while staying dynamic. Once that gap is gone, PDL exposes the smaller GPU-side opportunity in overlapping the work of two kernels.